1. Purpose
The first purpose of Urchin is to be a web based RSS aggregator and filter. The software allows the creation of new RSS feeds that consist of an collection of items from many sources, with the new RSS feeds themselves being URI addressable.
A secondary purpose is to facilitate the creation of new primary RSS feeds - the software distibution contains modules that help simplify the creation of RSS feeds from information stored in scrapable text formats or relation databases.
A suplimentary purpose is to help in the interchange of information
between RSS and non-RSS formats. Urchin can produce the results of a query in
any output format that can be defined as an XSL transformation of an RSS 1.0
document or by using an HTML::Template template. These outputs
are also URI addressable, enabling Urchin to function as a simple RSS
newsreader or to run a simple news portal.
2. Design
The development of Urchin has followed two design goals:
- Be as modular as possible, to allow the easy plugging together of different modules to meet the different purposes.
- Capture as much information from incoming RSS feeds as possible - for example, store all the 'extra' namespaced elements in an RSS 1.0 feed.
As always, the code is still a work in progress. See the wishlist for a list of desirable features that are not yet implemented.
3. Architecture
Click on the image below to see a schematic of the architechture of Urchin.

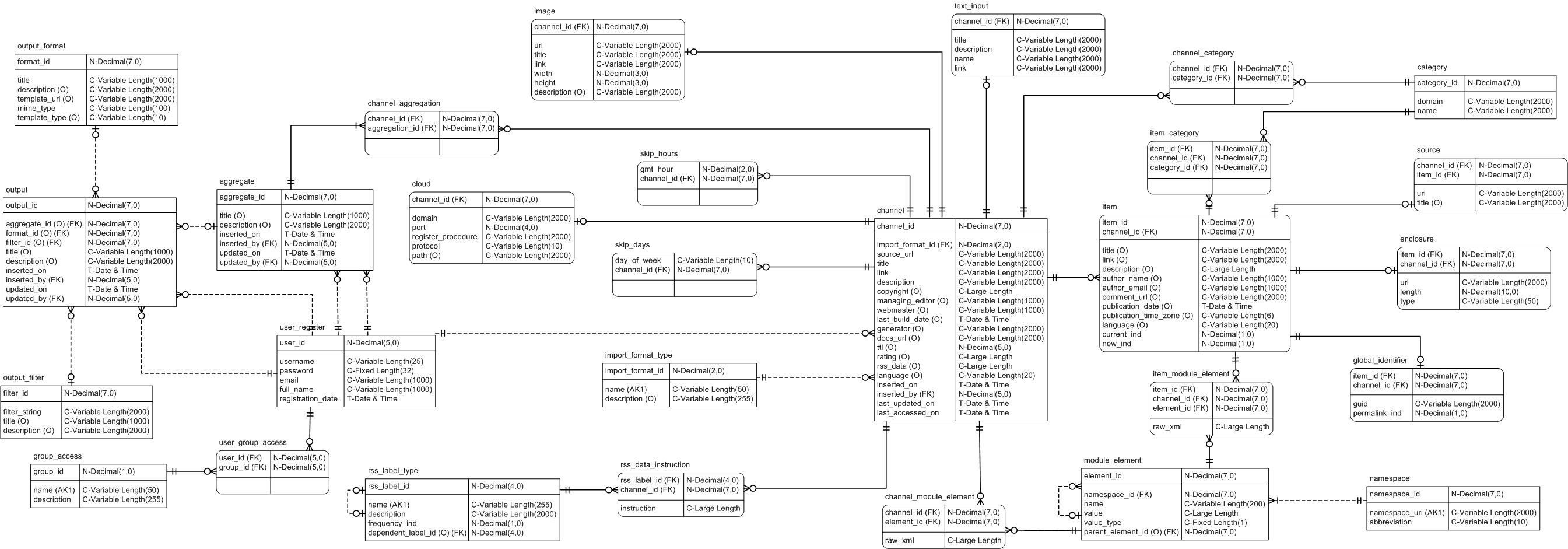
4. Urchin Data Model
For a full entity relationship diagram, see LogicalModel.jpg
{kind=link}
Here is a brief description of the purpose of the tables:
Tables channel, skip_hours,
skip_days, cloud
These store the channel level elements that are defined in the RSS 0.91, 0.92, 1.0 and 2.0 @@link specifications.
Tables item, enclosure,
source, global_identifier
These store the item level elements that are defined in the RSS 0.91, 0.92, 1.0 and 2.0 @@link specifications.
Tables channel_category,
item_category, category
These assocosiate RSS 0.9x/2.0 style categories with channels and items.
Tables module_element,
channel_module_element, item_module_element,
namespace
These four tables form a basic RDF triple store for capturing information contained in RSS 1.0 modules. For more information on RDF and RSS 1.0 modules, see http://www.w3.org/RDF/ and http://web.resource.org/rss/1.0/.
The predicate of an RDF triple is described by the fields
module_element.namespace_id and module_element.name
– namespace_id is a foreign key to the namespace table.
The full URI for the predicate is the namespace.namespace_uri
concatenated with the module_element.name.
The object of the triple is described by the
module_element.value and module_element.value_type
fields – value is the string value of the object,
value_type indicates whether that string should be interpreted
as a URI, a literal, or a blank node identifier.
The subject of the triple is indicated by the
module_element.parent_element_id field. If the subject of the
triple is an item, parent_element_id will be a foreign key to
the item_module_element table – that table in turn
associates an item.item_id with the triple. The URI for the
subect is (in this case) the value of item.link. Likewise, if
the subject of the triple is a channel, the
channel_module_element table is used in this way. If the subject
of the triple is neither an item nor a channel then it must be (in Urchin)
the object of a previously stored triple. In this case,
module_element.parent_element_id refers to another row in the
module_element table – the subject of the triple being the
same as the triple object stored in that refered-to row.
This arrangement forms a very basic RDF triple store - but one that is well suited to Urchin's purposes, as it effectively isolates triples from different sources. The provenance of any RDF statement encoded in this way can be efficiently traced to its source, and RDF graphs from different sources are not merged. This avoids the possibility of Urchin outputing statements about an item that were not made by that item's source. Of course, this is not the only way that aggregators can work, but is (we believe) appropriate for the messy world of RSS.
Tables aggregate,
channel_aggregation
The aggregate table lists the names of aggregations of
channels, and the channel_aggregation table lists the channels
that are in those aggregations. See the usage documentation for
more information on how these are used.
Table output_filter
This lists named filters - i.e. search strings that have been labeled. See Usage.html for more information on how these are used.
Table output_format
This table lists named custom output styles, how to generate them, and what mime_type they are. See the usage documentation for more information on how these are used.
Table output
This table is lists named outputs - i.e. associates a named filter and a named output format so that a specific search, with the results in a specific style, can be referenced by a simple label.
5. Urchin Perl Modules
For details of each module's API, see the perldocs. A brief description of the function of each module is given here.
Urchin
This is the base class from which all other modules inherit. It implements subroutines for Urchin-wide tasks - loading the configuration file, database access and fetching resources from the Web.
Urchin::Import
This is the base class for the data importing modules. It implements
subroutines for preparing an XML::RSS for saving to the Urchin
database - i.e. for mapping RSS 0.9x/2.0 elements to RSS 1.0 elements and
generating a set of RDF statements.
Urchin::Import::RSS
This module is used if data is to be extracted from an RSS feed.
Urchin::Import::Scrape
This module is used for extracting RSS data from a resource using regular
expressions. It implements a subroutine that constructs an
XML::RSS object by evaluating the regular expressions. See Usage.html for more details on how to use this.
Urchin::Import::DBI
This module is used for extracting RSS data from DBI sources. It
implements a subroutine that constructs an XML::RSS object by
evaluating a specially constructed SQL statement. See Usage.html for more details on how to use this.
Urchin::SaveData
This module performs the task of inserting data from an RSS file into the database. It's basic function is to traverse an RDF graph in order to save the data to the database.
Urchin::OutputFeed
This is the base class for the output modules. It's basic function is to
extract information from the Urchin database - it implements subroutines for
parsing the Urchin search syntax and constructing an XML::RSS
object from the resuls of a SQL query.
Urchin::OutputFeed::XSLT
This module is used to generate output using an XSL document. It runs the
XSL transformation on an RSS 1.0 serialization of an XML::RSS
object.
Urchin::OutputFeed::Template
This module is used to generate output using an
HTML::Template file. It sets up the channel_title,
channel_description, channel_link, items, item_title, item_description and
item_link variables for use in the template.
Urchin::OutputFeed::RDF::Core::Serializer
Urchin::OutputFeed::RDF::Core::Model::Serializer
These two modules are based on, and extend the functionality of, RDF::Core::Serializer and RDF::Core::Model::Serializer in order to be able to serialise an RDF model in the stricter RSS 1.0 format, and to allow the Urchin database to be used as an RDF model.
Specifically, the following capabilites were added to Urchin::OutputFeed::RDF::Core::Model::Serializer in order to be able to constrain the output to the RSS 1.0 style:
- to set the default namespace
- to specify an order in which elements from different namepaces are serialized
- to set a prefered subject type – i.e. triples whose subject is of that type will be serialised first
Urchin::OutputFeed::RDFSerialize
This module is a subclass of Urchin::OutputFeed::RDF::Core::Model::Serializer. It constrains RDF serialisation to the RSS 1.0 format, and allows the use of the Urchin database as a source of namespace abbreviation to URI mappings.
Urchin::OutputFeed::RDF::Core::Storage::Urchin
This module mimics the API of RDF::Core::Storage to allow the Urchin database to be seen as an RDF::Core::Storage triple store. Note that it currently only allows read access to that store.